
Alibaba has launched their latest Qwen 3.5 series, which consists of the Qwen 3.5 and 3.5 Plus, and both look awesome compared to their predecessors, and in some scenarios, it actually competes directly with Qwen 3 Max, which is their flagship model to date. But now, since the arrival of the 3.5, the 3 Max and its totally built on 397B parameters and is also available in a variety of sizes if you want to host them locally.
Coding
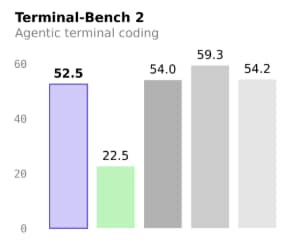
We have been testing Qwen 3.5 and comparing it to its competition, GPT 5.2. To be honest, the Qwen 3.5 can do better coding than the GPT 5.2, and when compared to the base Qwen 3 model, it excels. Our task was to create a 3D racing game. While both models had issues, Qwen just had a movement issue, which it had fixed easily, resulting in one of the best games I have seen, and Qwen 3, on the other hand, was struggling there to make it; it had more than 2 errors to fix, and the overall environment wasn’t as impressive either.
In the coding benchmarks, the Qwen 3.5 significantly outperforms the Qwen 3 max. In Terminal Bench 2, Kimi K2, it achieves a remarkable twofold improvement over the Qwen 3 max. Additionally, in other benchmarks, the Qwen 3.5 consistently outperformed the Qwen 3 max, and in some cases, it came very close to the Kimi K2. It also beats the Gemini 3 Pro in coding, which is an impressive achievement for the Qwen since the Qwen 3 was not as strong in coding. Now, however, it shows substantial improvement.
Improvements
The Alibaba Qwen 3.5 is trained on a significantly larger scale of visual-text tokens compared to the Qwen 3 with enriched Chinese/English, multilingual, stem, and reasoning data under stricter filtering. This enables cross-generation parity; the Qwen 3.5 397B matches the 1T base Qwen 3 Max, and since we now have the open-source 9B models, we tested them vs. their Qwen 3 counterparts, and thinking performance and the data we got from them were better than Qwen 3, and the best part was that the Qwen 3.5 9B took 16s in thinking and the 8B Qwen 3 took 32s, but the Qwen 3.5 offered a better output than the Qwen 3.

The Qwen 3.5 is built on the Qwen 3 next architecture, higher sparsity MOE, dated deltanet, gated attention, hybrid attention, stability optimisations, and multi-token prediction. Natively multimodal via early text-vision fusion and expanded visual/stem/video data, outperforming Qwen3-VL at similar scales. Increasing Multilingual coverage from 119 to 201 languages; a 250k vocabulary vs 150k boosts encoding/decoding efficiency from 10 to 60% across most languages. On Qwen Chat Now, users can choose from three modes: auto, thinking, and fast. With Auto Mode, users can leverage adaptive thinking, enabling them to think critically and utilise tools, including search. The thinking mode is designed for in-depth problem solving, while the fast mode provides data without consuming any tokens for thought processing.
Pricing, Availability
The Qwen 3.5 is available at Qwen Chat, Qwen CLI, etc., and recently they have released the open-source Qwen 3.5 models: the 397b full model and the 122b, 35b, 27b, 9b, 4b, 2b, and 0.8b. So if you want to run these powerful models locally or use the models for your own application, you can use these local models, and Qwen 3.5 has two models: one is the default Qwen 3.5 model we know, and the other is the Qwen 3.5 Plus model with a 1m context window and the model studio, features 1m free tokens for new users and costs $2.40 for 256k tokens and 256k to 1m is $3.00 in both non-thinking and thinking modes.
Security
For security, the Qwen 3.5 improves security by improving the performance of their local LLMs by making you use the local LLMs instead of using the cloud models for AI since the local models save the data in the GPU, etc., the cloud models use the data for their training data, and as the Qwen 3.5 models are trained on better data, they would give less unpredictable and more controlled outputs compared to the Qwen 3 series.
Speed
The Qwen 3.5, commonly in the Qwen chat, takes more time to generate a response than the Qwen 3. However, it provides more accurate answers. Most of the time spent by Qwen 3.5 is spent on thinking in thinking mode, while the Qwen 3 takes 20-25s to write it, so it feels like it’s taking more time to write it, Additionally when comparing Qwen 3.5 9B with the Qwen 3 8B, the 3.5 takes about 50-60% less time for thinking and makes a clean and better outputs than Qwen 3. This improvement is excellent for the model, as it reduces the time taken while enhancing the overall quality of the response.
We hope that you have enjoyed this article. For more information on electric vehicles, artificial intelligence, innovation, and the technology that will shape the future, continue to browse TechOrbis. At TechOrbis, our aim is to provide insightful analysis, honest views, and meaningful perspectives that extend beyond the news.
Follow TechOrbis on X/Twitter, Instagram, LinkedIn and Telegram to keep up with the latest news, trends, and tech talk. As a growing and independent source of news, every view, share, and mention helps us reach more people and continue to provide meaningful tech journalism.




