
Claude has launched the Claude Opus 4.5 model, which, according to the coding benchmarks, is best for coding, and in the SWE bench, it scores the top ranking out of all the models, which seems pretty excellent, and I have tried the model in C# coding, and the coding performance is pretty good, and it outshines the best coding models, even from OpenAI, like GPT 5.1 Max, but in Visual Code, esp. if you are using Copilot Pro, it’s the costliest option available.

Performance
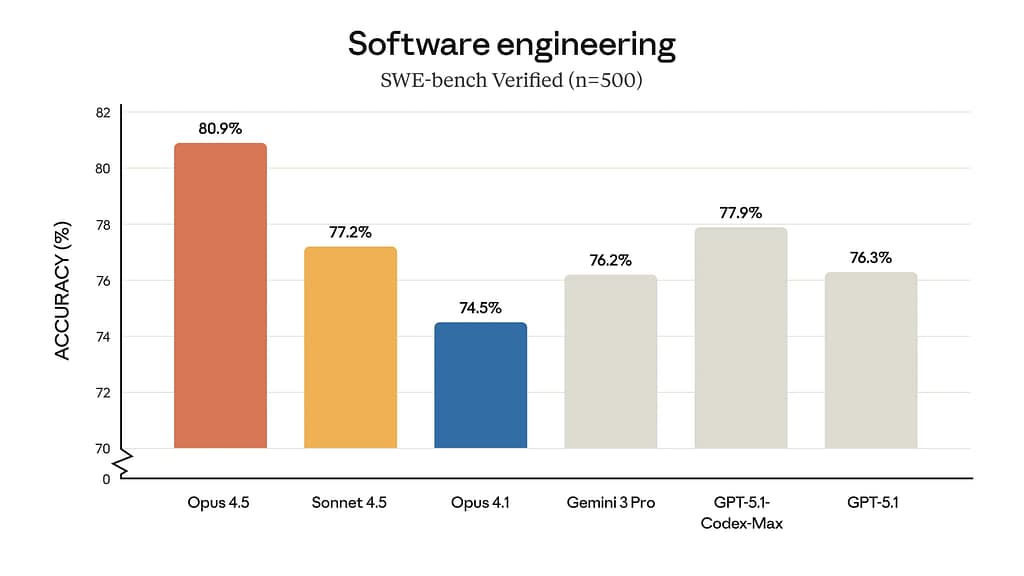
We have been testing the Claude Opus 4.5 for the last 2-3 weeks, and the coding performance is pretty good, better than any model out here, and I was testing it for C# dev for an app, and it was pretty good, giving the code some polishing it needed, and at one point I gave it 10 tasks, and all the tasks were done in just 1 day.
Yes, they are easier tasks, and once we did WPF UI migration in just 1-2 hours, and some of these tasks on the older generation Opus 4 or Sonnet 4.5 take a lot of time and guidance just to get the output right for us, but the Opus 4.5 is just too good if you want some dev and design something.
Improvements
It features a new planning mode, which creates understandable to-do lists before undertaking a massive task that requires a lot of work. Additionally, while migrating, as mentioned above, it can also create to-do lists. MD file for migration and let the MD file handle the migration rather than manually doing it, which isn’t that fast and causes a lot of issues. Most of our testing was done using GitHub Copilot Pro and Google’s Antigravity. While it has some downsides, like it takes a lot of tries sometimes to get something correct, sometimes it just identifies the issue and gets on to the task of fixing.
Availablity & Pricing
The Claude Opus 4.5 is currently available in the Claude Max and Pro plans, and those cost you 20 or 30 a month for the plan, respectively, and while the API costs for the model are $5 per million tokens in input and $25 per million tokens in output, prompt caching is 6.25 per million tokens in write and $0.50 per million tokens in read in prompt caching.
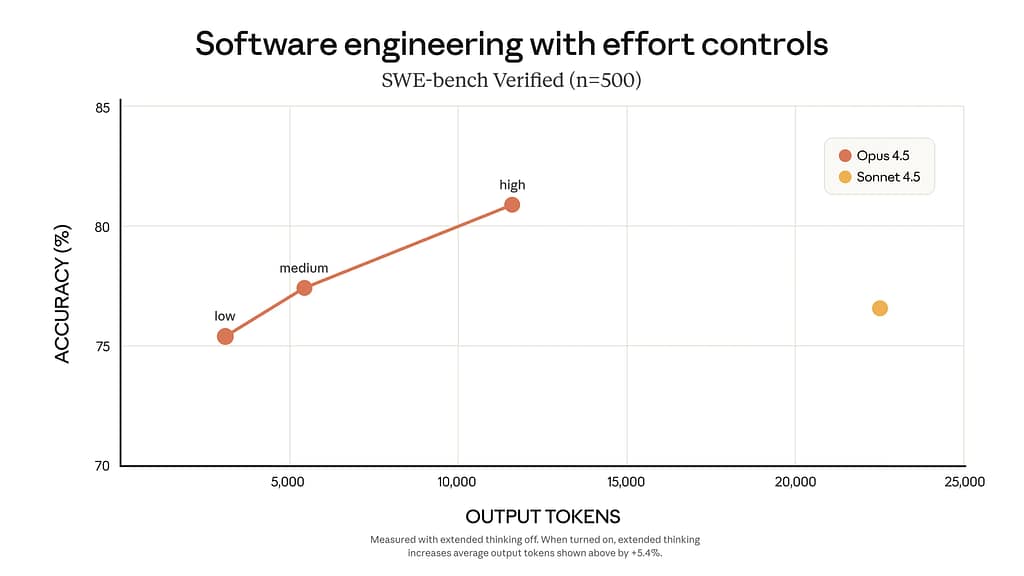
On GitHub Copilot Pro, the model is counted at a 3x rate, which means it takes 3x more requests than a standard model. For those wondering, this pricing is better than the Gemini 3 Pro API key if the user is targeting awesome coding performance and uses 76% fewer tokens to achieve the same performance as Sonnet 4.5 and exceeds Sonnet while using 48% fewer tokens.

image of GitHub Copilot Pro saying it’s counted at a 3x rate
Security
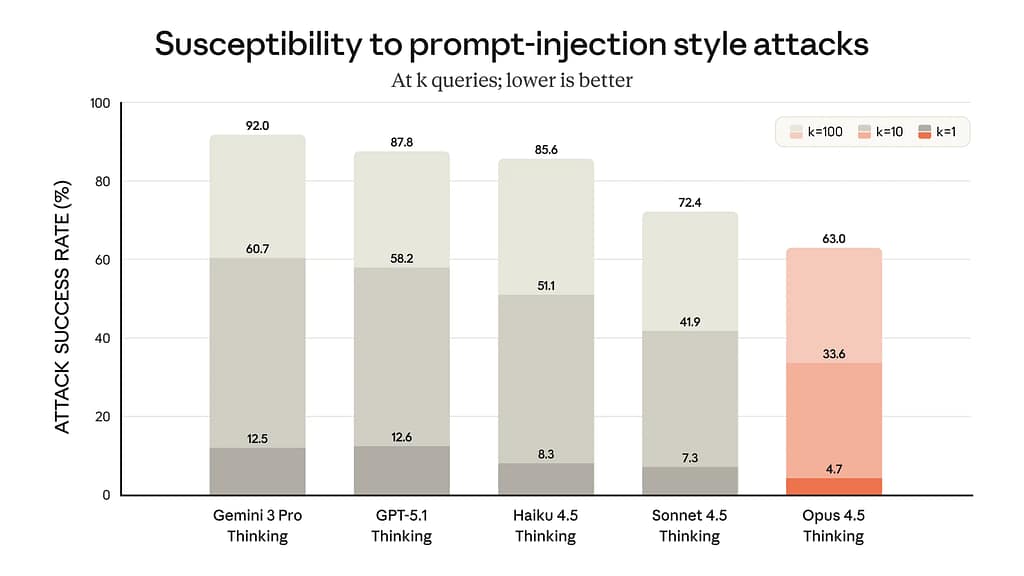
Speaking about security, the Claude Opus 4.5 features the lowest rate of security attacks on prompt-based attacks, which is pretty good since most of the guys who would use Claude are developers, and it scores lowest in concerning behaviour, which also means that the AI would not use any bad terms or try to downplay you.
Speed
Here is where the Claude Opus 4.5 shines fully. It’s better than the GPT 5.1 Codex Max because, thanks to the advancements, it can do a lot of stuff, like migration from X software to Y software, which is much faster than the competition, but it misses the files to update during the software migration, but generally it’s faster without that new MD file too since it can do a lot of work in minutes and polish it fully and fix all the bugs it might find in the code and can debug the app to see where the issues are coming from, which is pretty cool.
We hope that you have enjoyed this article. For more information on electric vehicles, artificial intelligence, innovation, and the technology that will shape the future, continue to browse TechOrbis. At TechOrbis, our aim is to provide insightful analysis, honest views, and meaningful perspectives that extend beyond the news.
Follow TechOrbis on X (formerly Twitter), Instagram, and LinkedIn to keep up with the latest news, trends, and tech talk. As a growing and independent source of news, every view, share, and mention helps us reach more people and continue to provide meaningful tech journalism.





