
OpenAI has launched its new GPT-5.4 on March 5th, and it combines the great coding performance from the GPT-5.3 Codex while improving how the model works across tools, software and environments, professional tasks involving spreadsheets, presentations and documents. While it actually arrived a lot faster than the 5.3 Codex, GitHub Copilot has been removed for some reason. which we will discuss later in the article.
Coding
We have been testing the 5.4 on the Codex app, and although OpenAI claims its performance is equivalent to that of 5.3 Codex, our experience suggests otherwise. In tasks related to Operating System refinement and code improvements, in both of the tasks, the 5.3 Codex is a better model. If you are looking for pure coding performance, the 5.3 Codex still offers better performance. Yeah, we have tried this model in our Android benchmark. While the thinking is good, the quota consumption was bad. While the 5.3 Codex didn’t work much, it did what was necessary and used 2% vs. 9% while thinking longer.
We had tried HTML coding on GPT-5.4; the performance was decent, but it had exceeded my expectations since there were a lot of issues with the codes, versus the 5.3 Codex, the animations and a lot more were in the areas of the GPT 5.3 Codex. I am also quite surprised by the performance of the Claude Sonnet 4.6, which is a midrange model, it’s quite comfortably beating the 5.4 in some parts of the webpage, the 5.4 also took around 20% to do the website, which isn’t good considering that the final code was around 400 lines and the 5.3 Codex had hover effects and took just 7 minutes while the 5.4 took 15 minutes for thinking.
Improvements
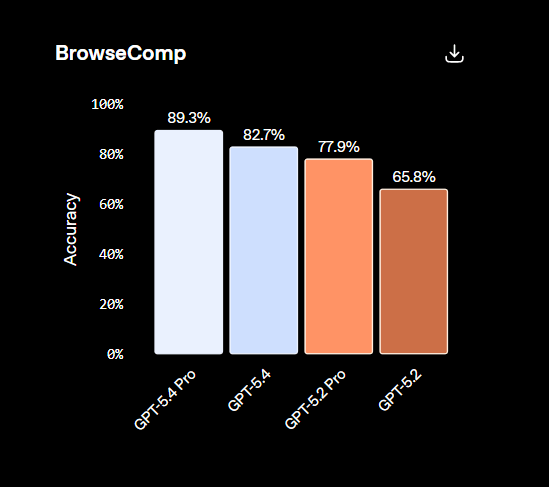
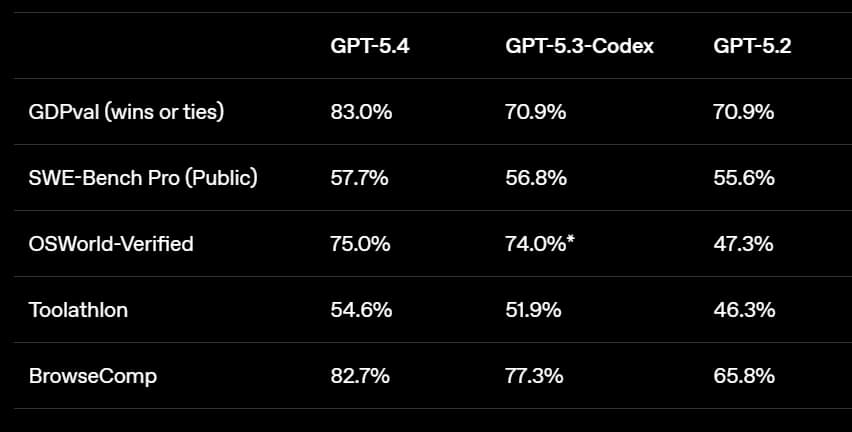
Building on the general reasoning capabilities of GPT 5.2, GPT 5.4 delivers even more consistent and polished results on real-world tasks that matter to professionals and on the GDPVal, which tests agent’s abilities to produce well-specified knowledge work across 44 occupations, and the GPT 5.4 achieves a new state of the art, matching or exceeding industry professionals in 83% of the comparisons compared to 70.9 for the GPT 5.2 and the 5.3 Codex. The GPT-5.4 can actually browse well, scoring 82.7 compared to the 65.8% achieved by the previous generation.
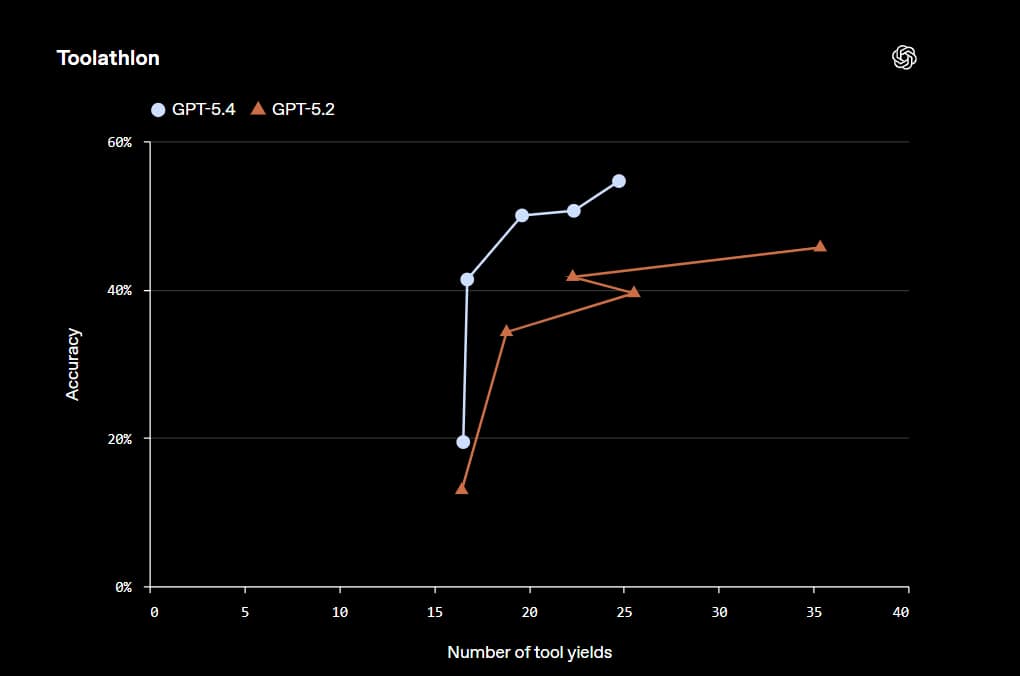
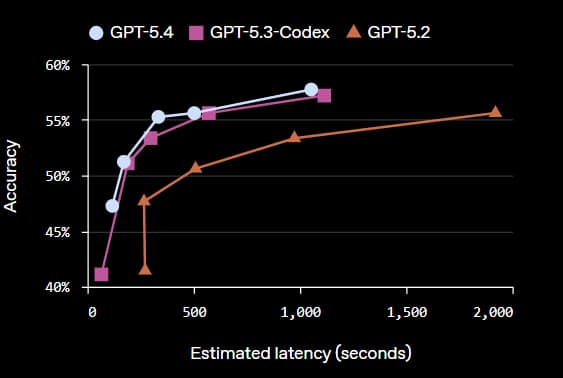
The GPT-5.4 is their most factual model yet. The GPT 5.4’s individual claims are 33% less likely to be false, and its full responses are 18% less likely to contain any errors compared to GPT-5.2. The GPT-5.4 is their first general-purpose model with native computer use capabilities and an OSS world-verified, which measures a model’s ability to navigate a desktop environment through screenshots and keyboard/mouse actions. The GPT-5.4 achieves a 75% success rate, which is a massive uplift from GPT-5.2 at 47.3% and surpasses human performance at 72.4%. In Toolathon, a benchmark that tests how well AI agents can use real-world tools and APIs to complete multi-step tasks, the accuracy has improved from 45.7% to 54.6%.
Availability, Pricing
The GPT-5.4 model is currently available only to users on paid ChatGPT plans, which is somewhat surprising, given that general access has been available to Go-tier and free users with rate limits. Free and Go-tier users must now use the GPT-5.3 model. Additionally, the 5.4 Mini and 5.4 Nano models have been released for users who wish to perform general (non-coding) tasks while maintaining lower costs. The model is available through the Codex application. It is worth noting that GitHub Copilot has removed the model from student plans and that GPT-5.4 pricing has increased, making it more expensive than GPT-5.3 Codex, with costs of approximately $2.50 per input unit and $15 per output unit.
Safety
The GPT 5.4 is being deployed with enhanced protections, which include expanded cybersecurity features such as monitoring systems and asynchronous blocking for higher-risk requests for customers using zero data retention surfaces. Because cybersecurity capabilities are inherently dual-use, we maintain a precautionary approach to deployment while continuing to refine our policies and classifiers. They’ve continued the safety research on chain of thought (COT) monitorability to understand how the models reason and help detect potential misbehaviour.
We hope that you have enjoyed this article. For more information on electric vehicles, artificial intelligence, innovation, and the technology that will shape the future, continue to browse TechOrbis. At TechOrbis, our aim is to provide insightful analysis, honest views, and meaningful perspectives that extend beyond the news.
Follow TechOrbis on X/Twitter, Instagram, LinkedIn and Telegram to keep up with the latest news, trends, and tech talk. As a growing and independent source of news, every view, share, and mention helps us reach more people and continue to provide meaningful tech journalism.





